Lists For Loops
1- Lists
Toward the end of the previous mission, we worked with this table:
track_name price currency rating_count_tot user_rating 0 Facebook 0.0 USD 2974676 3.5 1 Instagram 0.0 USD 2161558 4.5 2 Clash of Clans 0.0 USD 2130805 4.5 3 Temple Run 0.0 USD 1724546 4.5 4 Pandora - Music & Radio 0.0 USD 1126879 4.0 Data source: Mobile App Store data set (Ramanathan Perumal) Each value in the table is a data point. For instance, the first row has five data points:
Facebook 0.0 USD 2974676 3.5 A collection of data points make up a data set. We can understand our entire table above as a collection of data points, so we call the entire table a data set. We can see that our data set has five rows and five columns.
Typed out a sequence of data points and separated each with a comma: 'Facebook', 0.0, 'USD', 2974676, 3.5 Surrounded the sequence with brackets: ['Facebook', 0.0, 'USD', 2974676, 3.5] After we created the list, we stored it in the computer's memory by assigning it to a variable named row_1.
To create a list of data points, we only need to:
Separate the data points with a comma. Surround the sequence of data points with brackets. Now let's get a little practice with creating lists.
Instructions
Store the second row ('Instagram', 0.0, 'USD', 2161558, 4.5) as a list in a variable named row_2.
Store the third row ('Clash of Clans', 0.0, 'USD', 2130805, 4.5) as a list in a variable named row_3.
row_2 = ['Instagram', 0.0, 'USD', 2161558, 4.5]
print(row_2)
type(row_2)
row_3 = ['Clash of Clans', 0.0, 'USD', 2130805, 4.5]
print(row_3)
type(row_3)

2- Indexing
Two strings ('Facebook', 'USD') Two floats (0.0, 3.5) One integer (2974676) The ['Facebook', 0.0, 'USD', 2974676, 3.5] list has five data points. To find the length of a list, we can use the len() command
For small lists, we can just count the data points on our screens to find the length, but the len() command will prove very useful later on, when we work with lists containing thousands of elements (we'll see an actual example later in this mission).
Each element (data point) in a list has a specific number associated with it, called an index number. The indexing always starts at 0, so the first element will have the index number 0, the second element the index number 1, and so on.
To quickly find the index of a list element, identify its position number in the list, and then subtract 1. For example, the string 'USD' is the third element of the list (position number 3), so its index number must be 2 since 3 −1 = 2.
The index numbers help us retrieve individual elements from a list. Looking back at the list row_1 from the code example above, we can retrieve the first element (the string 'Facebook') with the index number 0 by running the code row_1[0].
As a side note, you may have noticed above that we used row_1[0] rather than print(row_1[0]). Recall from the first mission that the code editor displays the last line of code regardless of whether we use print() or not.
The syntax for retrieving individual list elements follows the model list_name[index_number]. For instance, the name of our list above is row_1 and the index number of the first element is 0 — following the list_name[index_number] model, we get row_1[0], where the index number 0 is in square brackets after the variable name row_1.
Instructions
In the code editor, you can already see the lists for the first three rows.
The fourth element in each list describes the number of ratings an app has received. Retrieve this fourth element from each list, and then find the average value of the retrieved numbers.
Assign the fourth element from the list row_1 to a variable named ratings_1. Don't forget that the indexing starts at 0.
Assign the fourth element from the list row_2 to a variable named ratings_2.
Assign the fourth element from the list row_3 to a variable named ratings_3.
Add the three numbers retrieved together and save the sum to a variable named total.
Divide the sum (now saved in the variable total) by 3 to get the average number of ratings for the first three rows. Assign the result to a variable named average.
row_1 = ['Facebook', 0.0, 'USD', 2974676, 3.5]
row_2 = ['Instagram', 0.0, 'USD', 2161558, 4.5]
row_3 = ['Clash of Clans', 0.0, 'USD', 2130805, 4.5]
ratings_1 = row_1[4]
ratings_2 = row_2[4]
ratings_3 = row_3[4]
total = ratings_1 + ratings_2 + ratings_3
average = total / 3
# print("Number of Ratings 1:", ratings_1)
# print("Number of Ratings 2:", ratings_2)
# print("Number of Ratings 3:", ratings_3)
# print("Total Ratings:", total)
print("Average Ratings:", average)

3- Negative Indexing
In Python, we have two indexing systems for lists:
Positive indexing: the first element has the index number 0, the second element has the index number 1, and so on. Negative indexing: the last element has the index number -1, the second to last element has the index number -2, and so on.
In practice, we almost always use positive indexing to retrieve list elements. Negative indexing is useful when we want to select the last element of a list — especially if the list is long, and we can't tell the length by counting.
Instructions
The last element in each list shows the average rating of each application.
Retrieve the ratings for the first three rows, and then find the average value of all the ratings retrieved.
Assign the last element from the list row_1 to a variable named rating_1. Try to take advantage of negative indexing.
Assign the last element from the list row_2 to a variable named rating_2.
Assign the last element from the list row_3 to a variable named rating_3.
Add the three ratings together and save the sum to a variable named total_rating.
Divide the total by 3 to get the average rating. Assign the result to a variable named average_rating.
row_1 = ['Facebook', 0.0, 'USD', 2974676, 3.5]
row_2 = ['Instagram', 0.0, 'USD', 2161558, 4.5]
row_3 = ['Clash of Clans', 0.0, 'USD', 2130805, 4.5]
ratings_1 = row_1[-1]
ratings_2 = row_2[-1]
ratings_3 = row_3[-1]
total = ratings_1 + ratings_2 + ratings_3
average = total / 3
# print("Number of Ratings 1:", ratings_1)
# print("Number of Ratings 2:", ratings_2)
# print("Number of Ratings 3:", ratings_3)
# print("Total Ratings:", total)
print("Average Ratings:", average)

4- Retrieving Multiple List Elements
Instructions
For Facebook, Instagram, and Pandora — Music & Radio, isolate the rating data in separate lists. Each list should contain the name of the app, the rating count, and the user rating. Don't forget that indexing starts at 0.
For Facebook, assign the list to a variable named fb_rating_data.
For Instagram, assign the list to a variable named insta_rating_data.
For Pandora — Music & Radio, assign the list to a variable named pandora_rating_data.
Compute the average user rating for Facebook, Instagram, and Pandora — Music & Radio using the data you stored in fb_rating_data, insta_rating_data, and pandora_rating_data.
You'll need to add the ratings together first, and then divide the total by the number of ratings. Assign the result to a variable named avg_rating. As a side note, we could calculate the average rating here a little bit better using the weighted mean — we'll learn about the weighted mean in the statistics courses.
row_1 = ['Facebook', 0.0, 'USD', 2974676, 3.5]
row_2 = ['Instagram', 0.0, 'USD', 2161558, 4.5]
row_4 = ['Pandora - Music & Radio', 0.0, 'USD', 1126879, 4.0]
fb_rating_data = [row_1[0], row_1[3], row_1[-1]]
insta_rating_data = [row_2[0], row_2[3], row_2[-1]]
pandora_rating_data = [row_4[0], row_4[3], row_4[-1]]
total_ratings = fb_rating_data[2] + insta_rating_data[2] + pandora_rating_data[2]
# total_users = fb_rating_data[1] + insta_rating_data[1] + pandora_rating_data[1]
avg_rating = total_ratings / 3
# print("Facebook Rating Data:", fb_rating_data)
# print("Instagram Rating Data:", insta_rating_data)
# print("Pandora Rating Data:", pandora_rating_data)
print("Average User Rating:", avg_rating)

5- List Slicing
In the last exercise, we retrieved the first, fourth, and last list elements to isolate the rating data. We can also retrieve the first three list elements to isolate the pricing data. When we select the first n elements (n stands for a number) from a list named a_list, we can use the syntax shortcut a_list[0:n]. In the example above, we needed to select the first three elements from the list row_3, so we used row_3[0:3].
When we selected the first three elements, we sliced a part of the list. For this reason, the process of selecting a part of a list is called list slicing.
Instructions
Select the first four elements from row_1 using a list slicing syntax shortcut. Assign the output to a variable named first_4_fb.
Select the last three elements from row_1 using a list slicing syntax shortcut. Assign the output to a variable named last_3_fb.
From row_5, select the list slice ['USD', 1126879] using a list slicing syntax shortcut. Assign the output to a variable named pandora_3_4.
row_1 = ['Facebook', 0.0, 'USD', 2974676, 3.5]
first_4_fb = row_1[:4]
last_3_fb = row_1[-3:]
row_5 = ['Pandora - Music & Radio', 0.0, 'USD', 1126879, 4.0]
pandora_3_4 = row_5[2:4]
print("First 4 Elements from row_1:", first_4_fb)
print("Last 3 Elements from row_1:", last_3_fb)
print("Selected Slice from row_5:", pandora_3_4)

6- List of Lists
Previously, we introduced lists as a better alternative to using one variable per data point. Instead of having a separate variable for each of the five data points 'Facebook', 0.0, 'USD', 2974676, 3.5, we can bundle the data points together into a list, and then store the list in a single variable.
So far, we've been working with a data set having five rows, and we've been storing each row as a list in a separate variable (the variables row_1, row_2, row_3, row_4, and row_5). If we had a data set with 5,000 rows, however, we'd end up with 5,000 variables, which will make our code messy and almost impossible to work with.
Instructions
In the code editor, we've already stored the five rows as lists in separate variables. Group together the five lists in a list of lists. Assign the resulting list of lists to a variable named app_data_set.
Compute the average rating of the apps by retrieving the right data points from the app_data_set list of lists.
The rating is the last element of each row. You'll need to sum up the ratings and then divide by the number of ratings.
Assign the result to a variable named avg_rating.
row_1 = ['Facebook', 0.0, 'USD', 2974676, 3.5]
row_2 = ['Instagram', 0.0, 'USD', 2161558, 4.5]
row_3 = ['Clash of Clans', 0.0, 'USD', 2130805, 4.5]
row_4 = ['Temple Run', 0.0, 'USD', 1724546, 4.5]
row_5 = ['Pandora - Music & Radio', 0.0, 'USD', 1126879, 4.0]
app_data_set = [row_1, row_2, row_3, row_4, row_5]
total_ratings = sum(row[-1] for row in app_data_set)
total_apps = len(app_data_set)
avg_rating = total_ratings / total_apps
print("Average Rating of the Apps:", avg_rating)

7- Opening a File
The data set we've been working with so far is an extract from a much larger data set:
id track_name size_bytes currency price rating_count_tot rating_count_ver user_rating user_rating_ver ver cont_rating prime_genre sup_devices.num ipadSc_urls.num lang.num vpp_lic 0 284882215 Facebook 389879808 USD 0.00 2974676 212 3.5 3.5 95.0 4+ Social Networking 37 1 29 1 1 389801252 Instagram 113954816 USD 0.00 2161558 1289 4.5 4.0 10.23 12+ Photo & Video 37 0 29 1 2 529479190 Clash of Clans 116476928 USD 0.00 2130805 579 4.5 4.5 9.24.12 9+ Games 38 5 18 1 ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... 7195 1097148221 S ou SS 4824064 USD 2.99 0 0 0.0 0.0 1.0.0 4+ Education 38 5 1 1 7196 977965019 みんなのお弁当 by クックパッド お弁当をレシピ付きで記録・共有 51174400 USD 0.00 0 0 0.0 0.0 1.4.0 4+ Food & Drink 37 0 1 1
Data source: Mobile App Store data set (Ramanathan Perumal)/ https://www.kaggle.com/ramamet4/app-store-apple-data-set-10k-apps
Our best strategy so far was to type each data point and bundle them efficiently into a list of lists. The data set above, however, has 7,197 rows and 16 columns, which amounts to 115,152 (7,197 × 16) data points — typing all that would take us days. We'd also be bound to make typing errors, which will eventually lead to wrong data and false conclusions. Fortunately, we can leverage Python to store this data set as a list of lists in a matter of seconds.
Instructions
Open the AppleStore.csv file and store it as list of lists.
Open the file using the open() command. Save the output to a variable named opened_file.
Read in the opened file using the reader() command (we've already imported reader() for you from the csv module). Save the output to a variable named read_file.
Transform the read-in file to a list of lists using the list() command. Save the list of lists to a variable named apps_data. Explore apps_data. You could:
Print its length using the len() command
Print the first row (the row describing column names)
Print the second and the third row (try to use list slicing here)
import csv
opened_file = open('AppleStore.csv', encoding='utf-8')
read_file = csv.reader(opened_file)
apps_data = list(read_file)
opened_file.close()
print("Length of apps_data:", len(apps_data))
print("First row (Column names):", apps_data[0])
print("Second row (App data):", apps_data[1])
print("Third row (App data):", apps_data[2])

8- Repetitive Processes
Previously in this mission, we were interested in computing the average rating of an app. This was a doable task when we were working with only five rows, but our data set now has 7,197 rows.
Retrieving 7,197 ratings manually is impractical because it can take a long, long time. We need to find a way to retrieve all 7,197 ratings in a matter of seconds.
Looking at the code example above, we see that a process keeps repeating: we select the last list element for each list within app_data_set. The app_data_set stores five lists, so we repeat the same process five times. What if we could tell Python directly that we want to repeat this process for each list in app_data_set?
Fortunately, we can do that — Python offers us an easy way to repeat a process, which helps us enormously when we need to repeat a process hundreds, thousands, or even millions of times.
Instructions
Use the new technique we've learned to print all the rows in the app_data_set list of lists. Essentially, you'll need to translate this pattern into Python syntax: for each list in the app_data_set variable, print that list.
Don't forget about indentation.
for app_data in app_data_set:
print(app_data)

9- For Loops
The technique we've just learned is called a loop. Because we always start with for (like in for some_variable in some_list:), this technique is known as a for loop.
The indented code in the body gets executed the same number of times as elements in the iterable variable. If the iterable variable is a list that has three elements, the indented code in the body gets executed three times. We call each code execution an iteration, so there'll be three iterations for a list that has three elements.
Instructions
Compute the average app rating for the apps stored in the app_data_set variable.
Initialize a variable named rating_sum with a value of zero outside the loop body.
Loop (iterate) over the app_data_set list of lists. For each of the five iterations of the loop (for each row in app_data_set):
Extract the rating of the app and store it to a variable named rating. The rating is the last element of each row.
Add the value stored in rating to the current value of the rating_sum.
Outside the loop body, divide the rating sum (stored in rating_sum) by the number of ratings to get an average value. Store the result in a variable named avg_rating.
rating_sum = 0
for app_data in app_data_set:
rating = float(app_data[-1])
rating_sum += rating
num_apps = len(app_data_set)
avg_rating = rating_sum / num_apps
print("Average App Rating:", avg_rating)

10- The Average App Rating
Now we move on to computing the average rating for the data set that has 7,197 rows. Remember we first need to open the file AppleStore.csv and transform it into a list of lists
Instructions
Compute the average app rating for all the 7,197 apps stored in the data set.
Initialize a variable named rating_sum with a value of zero.
Loop through the apps_data[1:] list of lists (make sure you don't include the header row). For each of the 7,197 iterations of the loop (for each row in apps_data[1:]):
Extract the rating of the app and store it to a variable named rating (the rating has the index number 7). Make sure you convert the rating value from a string to a float using the float() command.
Add the value stored in rating to the current value of the rating_sum.
Divide the rating sum (stored in rating_sum) by the number of ratings to get an average value. Store the result in a variable named avg_rating.
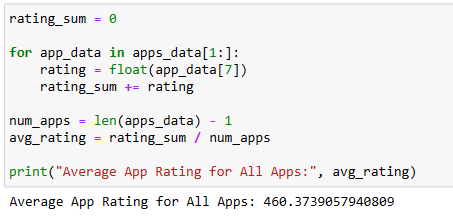
rating_sum = 0
for app_data in apps_data[1:]:
rating = float(app_data[7])
rating_sum += rating
num_apps = len(apps_data) - 1
avg_rating = rating_sum / num_apps
print("Average App Rating for All Apps:", avg_rating)
11- Alternate Way to Computer an Average
Now we'll learn an alternative way to compute the average rating value. Unlike other commands we've learned, notice that append() has a special syntactical usage, following the pattern list_name.append() rather than being simply used as append() (we'll get a better understanding of this syntactical quirk once we learn about functions and methods).
Instructions
Using the new technique we've learned, compute the average app rating for all of the 7,197 apps stored in our data set.
Initialize an empty list named all_ratings.
Loop through the apps_data[1:] list of lists (make sure you don't include the header row). For each of the 7,197 iterations of the loop:
Extract the rating of the app and store it to a variable named rating (the rating has the index number 7). Make sure you convert the rating value from a string to a float.
Append the value stored in rating to the list all_ratings.
Compute the sum of all ratings using the sum() command.
Divide the sum of all ratings by the number of ratings, and assign the result to a variable named avg_rating.
all_ratings = []
for app_data in apps_data[1:]:
rating = float(app_data[7])
all_ratings.append(rating)
total_ratings = sum(all_ratings)
num_ratings = len(all_ratings)
avg_rating = total_ratings / num_ratings
print("Average App Rating for All Apps:", avg_rating)

Tidak ada komentar:
Posting Komentar